
Fangrui Zhu
Ph.D. Student,
Northeastern University
Boston, MA, U.S.
zhu.fang@northeastern.edu
CV
∙
Google Scholar∙
GitHub ∙
X (Twitter)
About Me
I am a final-year PhD at Khoury College of Computer Sciences, Northeastern University, advised by Prof. Huaizu Jiang. I am also fortunate to collaborate closely with Dr. Jianwei Yang. Before that, I received my Bachelor's degree in Software Engineering from Tongji University and Master's degree in Statistics from Fudan University.
Research Interests
3D Reasoning, Multimodal LLMs, Video Understanding.
Publications and Preprints
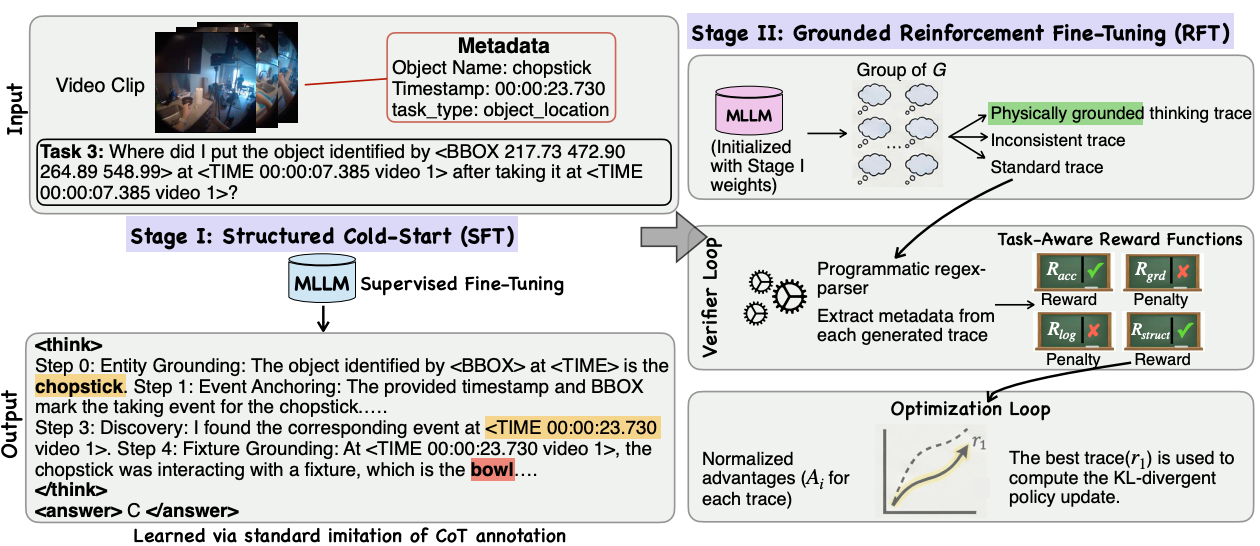
EgoReasoner: Learning Egocentric 4D Reasoning via Task-Adaptive Structured Thinking
Fangrui Zhu,
Yunfeng Xi,
Jianmo Ni,
Mu Cai,
Boqing Gong,
Long Zhao,
Chen Qu,
Ian Miao,
Yi Li,
Cheng Zhong,
Huaizu Jiang,
Shwetak Patel,
Preprint.
[PDF]
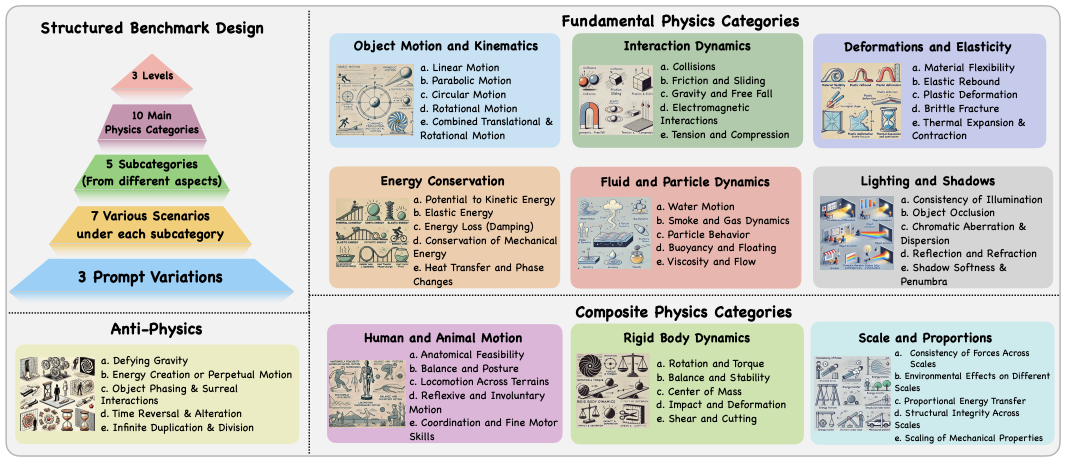
PhyWorldBench: A Comprehensive Evaluation of Physical Realism in Text-to-Video Models
Jing Gu,
Xian Liu,
Yu Zeng,
Ashwin Nagarajan,
Fangrui Zhu,
Daniel Hong,
Yue Fan,
Qianqi Yan,
Kaiwen Zhou,
Ming-Yu Liu,
Xin Eric Wang,
International Conference on Learning Representations (ICLR Oral), 2026.
[PDF]
[Code]
[Project Page]
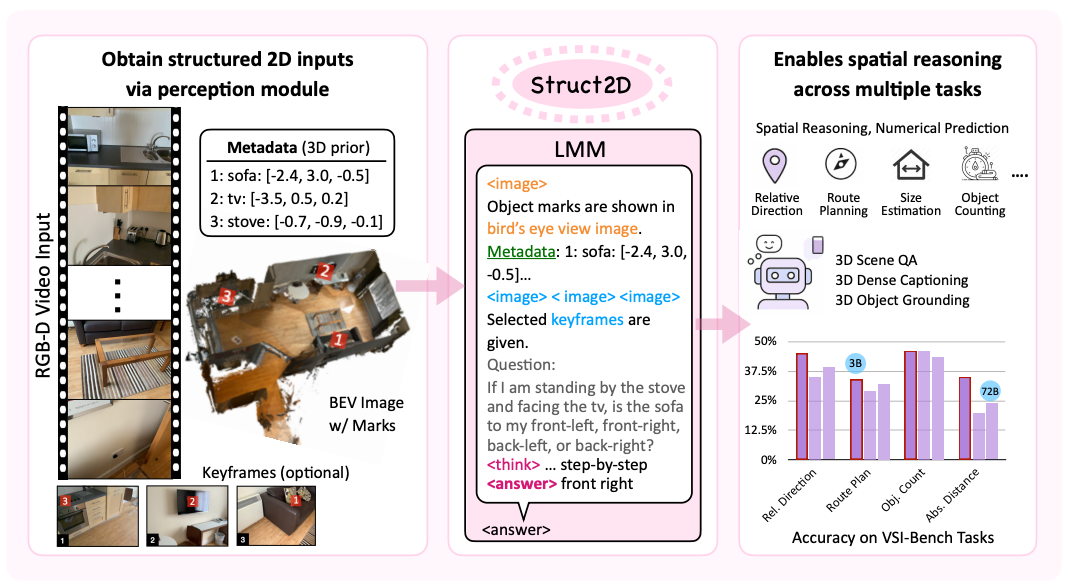
Struct2D: A Perception-Guided Framework for
Spatial Reasoning in Large Multimodal Models
Fangrui Zhu*,
Hanhui Wang*,
Yiming Xie,
Jing Gu,
Tianye Ding,
Jianwei Yang,
Huaizu Jiang.
(* equal contribution)
Annual Conference on Neural Information Processing Systems (NeurIPS), 2025.
[PDF]
[Code]
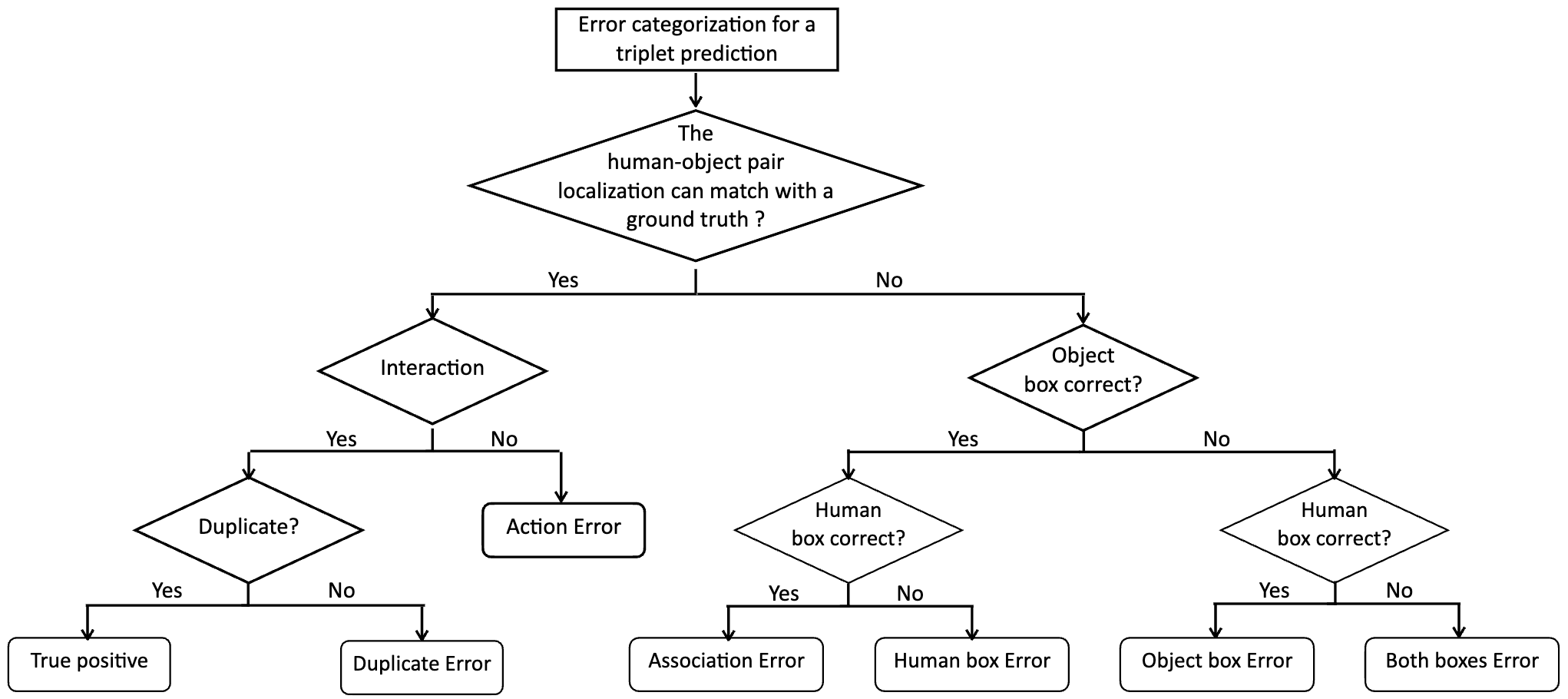
Diagnosing human-object interaction detectors
Fangrui Zhu,
Yiming Xie,
Weidi Xie,
Huaizu Jiang.
International Journal of Computer Vision (IJCV), 2025.
[PDF]
[Code]
[Project Page]
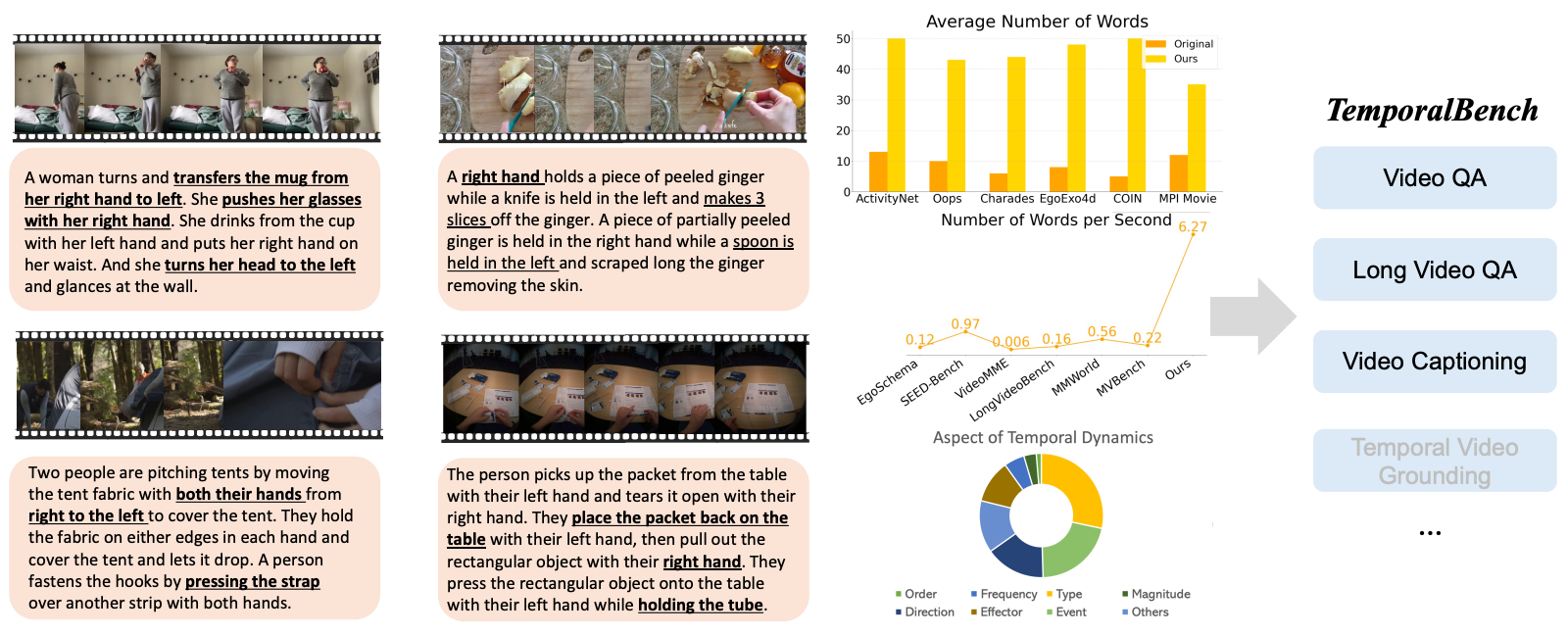
TemporalBench: Benchmarking Fine-grained Temporal Understanding for Multimodal Video Models
Mu Cai,
Reuben Tan,
Jianrui Zhang,
Bocheng Zou,
Kai Zhang,
Feng Yao,
Fangrui Zhu,
Jing Gu,
Yiwu Zhong,
Yuzhang Shang,
Yao Dou,
Jaden Park,
Jianfeng Gao,
Yong Jae Lee,
Jianwei Yang.
arXiv, 2024.
[PDF]
[Code]
[Project Page]
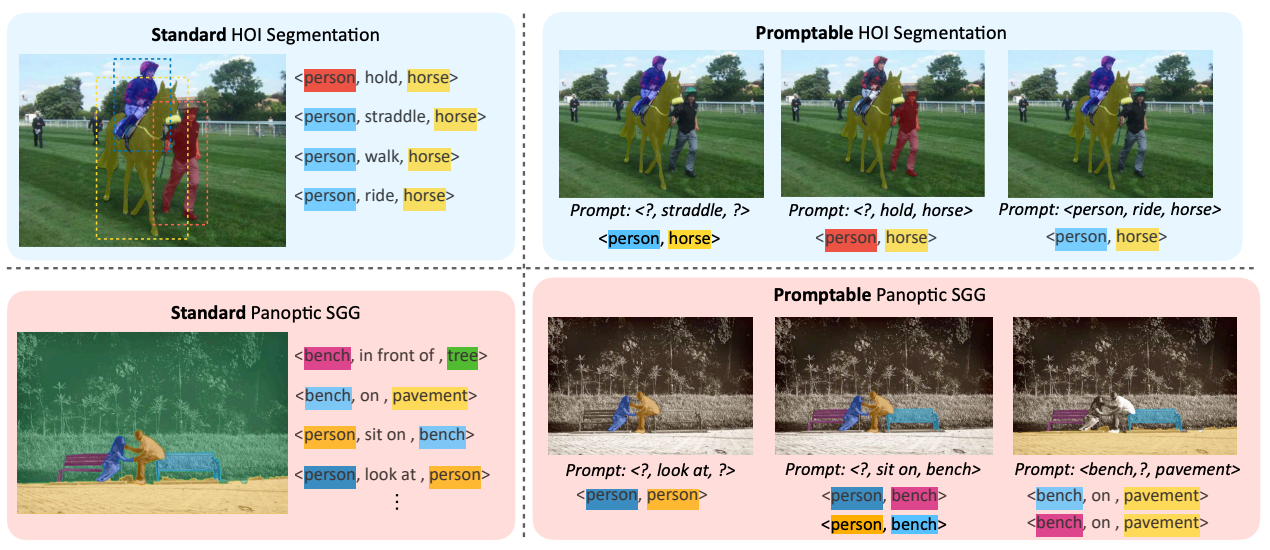
Towards Flexible Visual Relationship Segmentation
Fangrui Zhu,
Jianwei Yang,
Huaizu Jiang.
Annual Conference on Neural Information Processing Systems (NeurIPS), 2024.
[PDF]
[Code]
[Project Page]
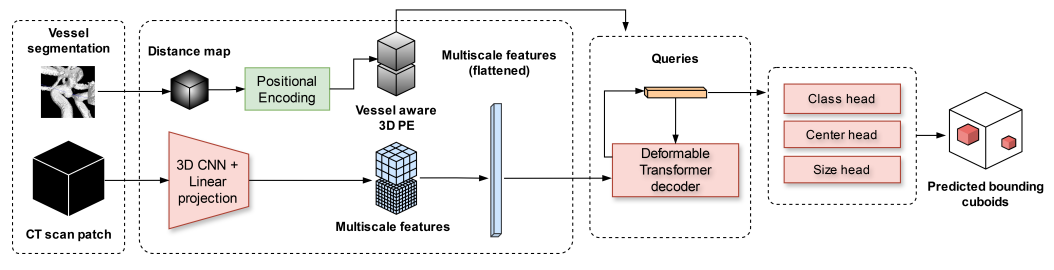
Vessel-Aware Aneurysm Detection Using Multi-scale Deformable 3D Attention
Alberto M. Ceballos-Arroyo,
Hieu T Nguyen,
Fangrui Zhu, Shrikanth M Yadav, Jisoo Kim, Lei Qin, Geoffrey Young,
Huaizu Jiang.
International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), 2024.
[PDF]
[Code]
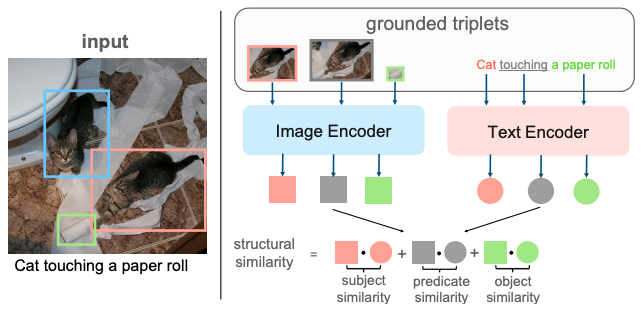
Zero-shot referring expression comprehension via structural similarity between images and captions
Zeyu Han,
Fangrui Zhu,
Qianru Lao,
Huaizu Jiang.
Computer Vision and Pattern Recognition (CVPR), 2024.
[PDF]
[Code]
Self-supervised video object segmentation
Fangrui Zhu,
Li Zhang,
Yanwei Fu,
Guodong Guo,
Weidi Xie.
arXiv, 2020.
[PDF]
Long-Term Cloth-Changing Person
Re-identification
Xuelin Qian,
Wenxuan Wang,
Li Zhang,
Fangrui Zhu,
Yanwei Fu,
Tao Xiang,
Yugang Jiang,
Xiangyang Xue.
Asian Conference on Computer Vision (ACCV), 2020.
[PDF]
[Project Page]
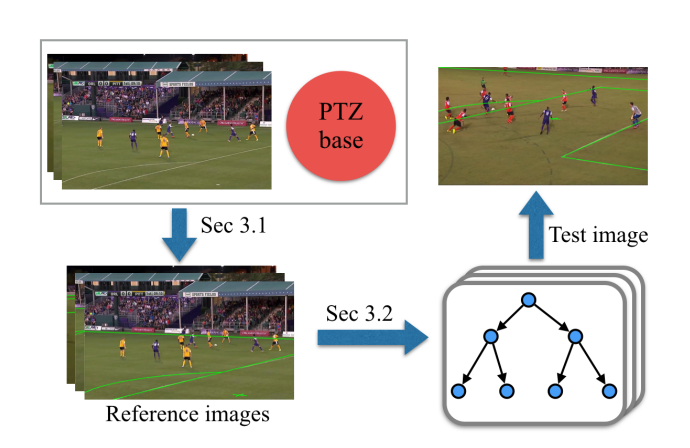
A Two-Point Method for PTZ Camera Calibration in Sports
Jianhui Chen,
Fangrui Zhu,
James J Little.
Winter Conference on Applications of Computer Vision (WACV), 2018.
[PDF]
[Code]
Service
Reviewer for ICCV2021, ECCV2022, BMVC2022, CVPR2022-2025, ICCV2023, ECCV2024, NeurIPS2024, ICML2025, IEEE TPAMI.
Misc
I enjoy staying active with Pilates, Gyrotonic, and Snowboarding.